Iterative Summarization using LLMs
After being busy for the first part of the year, I finally have a bit of time to work on this blog. After a lot of thinking about how to best fit it into my schedule, I've decided to attempt to write shorter posts. Although I do get a lot of satisfaction writing long posts, it's not practical because of the time commitment. Better to break it up into smaller parts to be able to "ship" often rather than perfect each post. This also allows me to experiment with smaller scoped topics, which hopefully will keep more more motivated as well. Speaking of which...
This post is about answering a random thought I had the other day: what would happen if I kept passing an LLM's output back to itself? I ran a few experiments of trying to get the LLM to iteratively summarize or rephrase a piece of text and the results are... pretty much what you would expect. But if you don't know what to expect, then read on and find out what happened!
Table of Contents
1 Setup
The setup for experiments is really simple. Start with one of two pieces of
data: A long summary of all my blog posts from my personal site, or an LLM generated list of 100 random facts. Next, run
an LLM asking it to either: Summarize the following: {data} or
Rephrase the following: {data}. Take the output response, repeat 50
times and observe!
I also used this system prompt to help not lose too much data:
The following is a conversation with an AI assistant. The assistant is helpful, creative, clever, and very friendly. The assistant will attempt to give a response that is concise but ensures that all the key points are included when relevant.
I ran combinations of the above using gpt-4o and gpt-3.5-turbo,
and temperatures of \(0.0, 0.5, 1.0\). That's it! You can find my hacky
code on Github for these
experiments. Let's take a look to see what happened.
2 Experiments
2.1 Blog Data
First up are the blog post experiments shown in Figure 1 (never mind the 42
in the label, that's just the random seed) where the X-axis is the iteration
number and the Y-axis is the length of the response. For these experiments, I only
ran the "Summarize" prompt. The input data to this is
a summary by gpt-4o of a scrape of my blog, which you can look at
here.
It's about 7.6 KB in size compared to all my blog posts which are closer to
500KB.
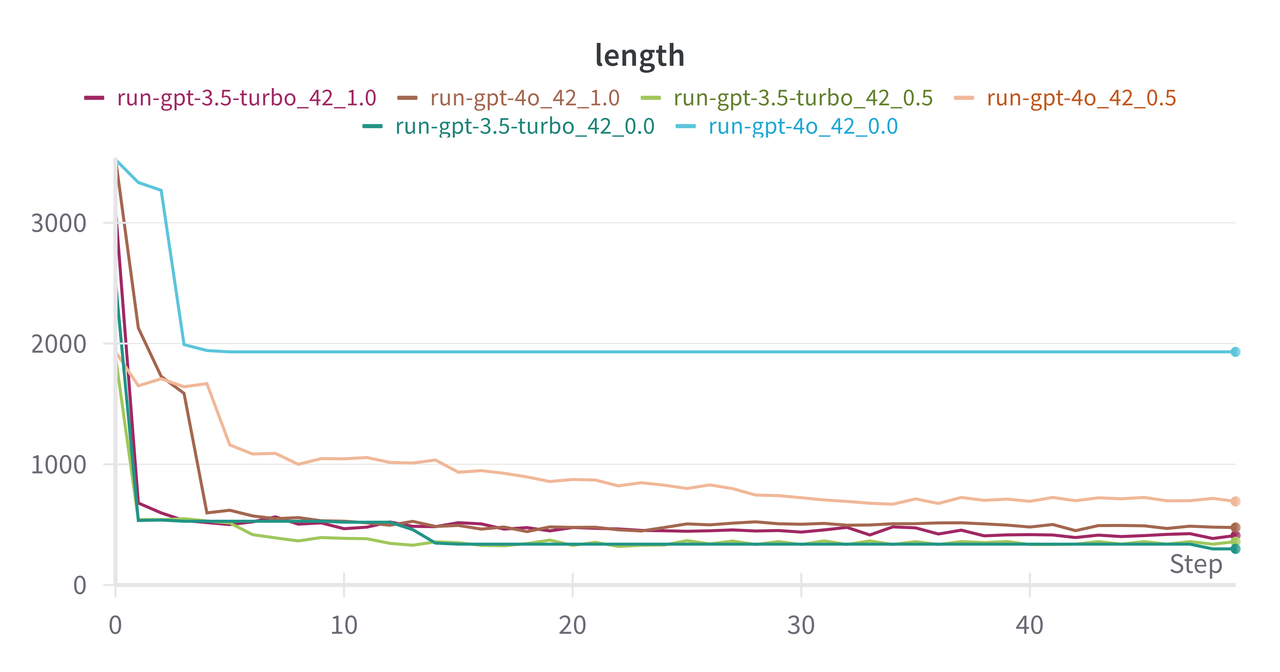
Figure 1: Length of response from LLM's for iterative summarization across {gpt-4o, gpt-3.5-turbo} and temperatures of {0.0, 0.5, 1.0}.
In the first iteration, the LLM drops a lot of bytes cutting the size down
by more than half in all cases. Across almost all runs, the LLM's converged to
a pretty short response. Here's an example from gpt-4o_42_0.5 run:
The author, an AI and data science expert affiliated with BorealisAI and the University of Toronto, blends their professional knowledge with interests in sports, music, and technology to offer varied reading suggestions. They are a respected speaker, patent holder, and researcher whose reflections from 2020-2022 emphasize family, career growth, humility, and mentorship. At Rubikloud, they prioritized people and learning, contributing to its acquisition by Kinaxis. Throughout the pandemic, they maintained routines and optimized their work environment. Their 2019 review highlights professional achievements, personal health, team management, and includes an inspiring story about Mozart.
I mean as a summary of my entire blog in less than 1000 bytes, it's not
terrible. But the original summary, which was already greatly condensed from
all my writing, is 7x the size. The only outlier is gpt-4o at
temperature=0.0, here's the summary it gave:
The author is a Research Director at BorealisAI and an Adjunct Professor at the University of Toronto, specializing in Electrical and Computer Engineering. He enjoys sports, music, technology, and economics, and values simplicity and flexibility. His expertise includes AI for hardware design automation and teaching data structures and algorithms. He recommends "Outliers" by Malcolm Gladwell and "The Intelligent Investor" by Benjamin Graham.
His contributions to data science and AI include talks, patents, and papers, focusing on machine learning, decision automation, and AI in retail, with notable patents in user behavioral segmentation and influencer analysis.
In his yearly reviews, he reflects on professional and personal milestones:
2022: A stable year with family time and professional highlights, emphasizing mindfulness and quality time.
2021: Adaptation to the pandemic, starting at BorealisAI, and hopes for better social connections and fitness.
2020: Significant changes like his daughter's birth, buying a house, and Rubikloud's acquisition by Kinaxis, with challenges in maintaining hobbies and fitness.
Reflecting on six years at Rubikloud, he emphasizes the importance of people, learning, and resilience, with the acquisition by Kinaxis marking a new chapter. Lessons from the pandemic include adjusting routines, managing stress, and improving remote work efficiency.
The 2019 review covers professional highs and emotional lows, contributions to Rubikloud's growth, and challenges in work-life balance and burnout. Teaching was fulfilling, and personal hobbies progressed, with aims to improve health and fitness in 2020.
He reviews books like "Tuesdays with Morrie" and "Radical Candor," offering insights on cherishing life, honest feedback, and learning strategies. A humorous story about Mozart highlights self-sufficiency and the importance of self-motivation and independence.
It's a respectable 2000 characters long and still maintains some of the
original format. Perhaps what is most interesting here is that it looks like
that gpt-4o reached a fixed point in this configuration. The plateau in
Figure 1 in fact did produce the same summary over and over again. This obviously
could only really happen at temperature 0 where each run is (mostly) deterministic.
gpt-3.5-turbo showed similar behavior with a shorter summary at this
temperature but it did drop a few words at iteration 14 and again at iteration
49. This is likely because of the slight non-determinism of how OpenAI runs
the models even with a fixed random seed.
At any other larger temperature, we would expect deviation, which explains all
the wiggles on the other runs. We also see that the other gpt-4o runs
with larger temperature did have similar length summaries in the first few
iterations, but quickly devolved into much shorter ones where I assume it could
not make it more concise. The gpt-3.5-turbo run's response length drops
pretty quickly after the first iteration though.
All these results aren't too surprising except for the "near" fixed point that we saw with gpt-4o, temperature 0. It just seems unlikely to me that it would reproduce the exact same text instead of modifying a word here or there. These LLM's are mysterious blackboxes indeed.
2.2 Random Fact Data
In this set of experiments, I first asked gpt-4o to generate 100 random facts
that I would then use as input data, which I put on
Github.
Similar to above, I then asked the LLM to either summarize or rephrase the input data
over and over again. Figure 2 shows the results in terms of lines (where each
fact is on a line).
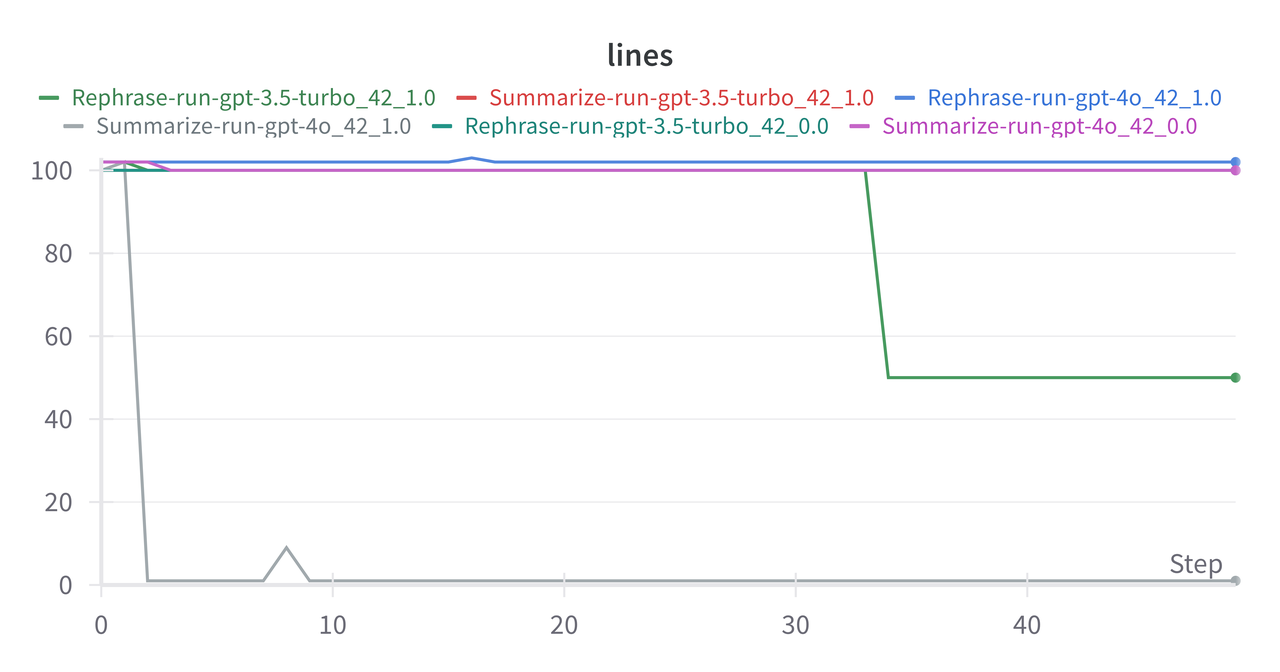
Figure 2: Number of lines of response from LLM's for iterative summarization across a sample of experiments from {gpt-4o, gpt-3.5-turbo} and temperatures of {0.0, 0.5, 1.0} and two different prompts.
In this chart I only included a sample because all of the other experiments
were pretty boring -- they just mirrored the majority, which were able to
retain all 100 lines of facts. The two outliers were gpt-3.5-turbo
with the rephrasing prompt and gpt-4o with the summary prompt, both at
temperature \(1.0\). The gpt-3.5-turbo at iteration 35 randomly
decided to drop half of the facts and spit out a list of only 50 lines long.
Not sure what happened here, but I guess it just randomly decided to stop!
The gpt-4o run decided to drop the list format entirely on iteration 3
and just summarize the list with a short paragraph, which obviously dropped a
lot of information.
Unsurprisingly both happened at temperature \(1.0\), and maybe slightly surprisingly, not all runs at \(1.0\) had this issue. There were two other runs paralleling the ones above but with the opposite prompt that kept all 100 facts. This is just another good reminder that LLM behavior is indeed random and the randomness scales with temperature. Consequently, they are not easy to control at all.
3 Discussion
Here are a couple of other random thoughts I had:
-
I kept getting an error at temperature \(2.0\):
Error code: 500 - {'error': {'message': 'Failed to create completion as the model generated invalid Unicode output. Unfortunately, this can happen in rare situations. Consider reviewing your prompt or reducing the temperature of your request. You can retry your request, or contact us through our help center at help.openai.com if the error persists. (Please include the request ID req_XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX in your message.)', 'type': None, 'param': None, 'code': None}}
I guess at that temperature the output token distribution gets really flat and you get weird non-Unicode characters being selected? I probably should have tried to do some runs at temperature \(1.5\) or something like that but I'll leave that to someone else if they're curious.
I used Weights & Biases for all the experimentation (maybe you can tell from the charts?), and I like it! I played around with it a bit before, and decided that I should keep using it to get more familiar with it. It's a nice time saver to not have to manage all the logged data and code up the right visualizations. Especially with Github CoPilot helping smooth the coding part, I was able to do most of what I wanted pretty easily. For organizations, there are obvious lock-in problems. From an enterprise point of view, it's also pretty expensive (so I hear) but I guess at that scale you can afford it.
4 Conclusion
That's it! Possibly my shortest post yet, and kind of fun to just randomly play around without doing anything too grand. I haven't given up on ML or math heavy stuff though, just wanted to prove to myself that I could write a short post and ease myself back into it. See you next time!