Lagrange Multipliers
This post is going to be about finding the maxima or minima of a function subject to some constraints. This is usually introduced in a multivariate calculus course, unfortunately (or fortunately?) I never got the chance to take a multivariate calculus course that covered this topic. In my undergraduate class, computer engineers only took three half year engineering calculus courses, and the fourth one (for electrical engineers) seems to have covered other basic multivariate calculus topics such as all the various theorems such as Green's, Gauss', Stokes' (I could be wrong though, I never did take that course!). You know what I always imagined Newton saying, "It's never too late to learn multivariate calculus!".
In that vein, this post will discuss one widely used method for finding optima subject to constraints: Lagrange multipliers. The concepts behind it are actually quite intuitive once we come up with the right analogue in physical reality, so as usual we'll start there. We'll work through some problems and hopefully by the end of this post, this topic won't seem as mysterious anymore 1.
Motivation
One of the most common problems of calculus is finding the minima or maxima of a function. We see this in a first year calculus course where we take the derivative, set it to \(0\), and solve for \(x\). Although this covers a wide range of applications, there are many more interesting problems that come up that don't fit into this simple mold.
A few interesting examples:
A simple (and uninteresting) question might be: "How do I minimize the aluminum (surface area) I need to make this can?" It's quite simple: just make the can really, really small! A more useful question might be: "How do I minimize the aluminum (surface area) I need to make this can, assuming that I need to hold \(250 cm^3\) of liquid?"
Milkmaid problem: Suppose we're a milkmaid (\(M\)) in a large flat field trying to get to our cow (\(C\)) as fast as we can (so we can finish milking it and get back to watching Westworld). Before we can milk the cow, we have to clean out our bucket in the river nearby (defined by \(g(x,y)=0\)). The question becomes what is the best point on the river bank (\((x,y)\)) to minimize the total distance we need to get to the cow? We want to minimize distance here but clearly we also have the constraint that we must hit the river bank first (otherwise we would just walk in a straight line).
Finding the maximum likelihood estimate (MLE) of a multinomial distribution given some observations. For example, suppose we have a weighted six-sided die and we observe rolling it \(n\) times (i.e. we have the count of the number of times each side of the die has come up). What is the MLE estimate for each of the die probabilities (\(p_1, \ldots, p_6\))? It's clear we're maximizing the likelihood function but we're also subject to the constraint that the probabilities need to sum to \(1\), i.e. \(\sum_{i=1}^6 p_i = 1\).
We'll come back to these and try to solve them a bit later on.
The reason why these problems are more interesting is because many real-world impose constraints on what we're trying to minimize/maximize (reality can be pretty annoying sometimes!). Fortunately, Lagrange multipliers can help us in all three of these scenarios.
Lagrange Multipliers
The Basics
Let's start out with the simplest case in two dimensions since it's easier to visualize. We have a function \(f(x, y)\) that we want to maximize and also a constraint \(g(x, y)=0\) that we must satisfy. Translating this into a physical situation, imagine \(f(x, y)\) defines some hill. At each \((x,y)\) location, we have the height of the hill. Figure 1 shows this as a blue (purple?) surface. Now image we draw a red path (as shown in Figure 1) on our \((x, y)\) plane, defined by \(g(x, y)=0\). We wish to find the highest point on the hill that stays on this red path (i.e. maximize \(f(x,y)\) such that \(g(x,y)=0\)).
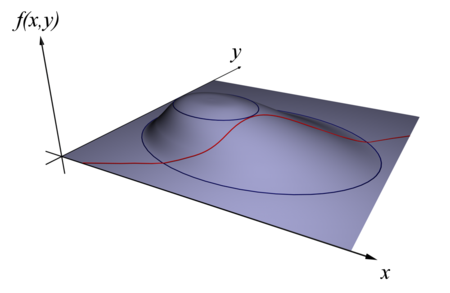
Figure 1: A 3D depiction of \(f(x,y)\) (blue surface) and \(g(x,y)\) (red line). (source: Wikipedia)
If we imagine ourselves trying to solve this problem in the physical world, there is (at least) one easy way to go about it: Keep walking along the red path, which potentially will take you up and down the hill, until you find the highest point (\(f(x,y)\) maximized). This brute force approach may be a simple way to achieve our goal but remember that \(g(x,y)=0\) might be infinitely long so it's a bit less practical. Instead, we'll do something a bit less exhaustive and identify candidate points along the path that may end up being maxima (i.e. necessary conditions).
Using our original idea of walking along the path, how do we know when we've potentially come across a candidate maxima point? Well, if we are walking uphill for a while along the path and then suddenly start walking downhill. If this sounds familiar, this resembles the idea of setting derivative to \(0\). In higher dimensions the generalization of the derivative is a gradient but we're not simply setting it to \(0\) because, remember, we're actually walking along the \(g(x,y)\) path.
Gradients
The gradient, denoted with the \(\nabla\) symbol, defines a vector of the \(n\) partial derivatives of a function of several variables: \(\nabla f(x,y) = (\frac{\partial f(x,y)}{\partial x}, \frac{\partial f(x,y)}{\partial y})\). Similar to a single variable function, the direction of the gradient points in the direction of the greatest rate of increase and its magnitude is the slope in that direction.
By this theorem, a \(\nabla f\)'s direction is either zero or perpendicular to contours (points at the same height) of \(f\). Using the analogy from Wikipedia, if you have two hikers at the same place on our hill. One hikes in the direction of steepest ascent uphill (the gradient). The other one is more timid and just walks along the hill at the same height (contour lines). The theorem says that the two hikers will (initially) walk perpendicular to each other.
There are two cases to consider if we've walked up and down the hill while staying along our path. Either we've reached the top of the hill and the gradient of \(f(x,y)\) will be zero. Or while walking along the path \(g(x,y)=0\), we have reached a level part of \(f(x,y)\) which means our \(f\) gradient is perpendicular to our path from the theorem in the box above. But since for this particular point, our path follows the level part of \(f\), the gradient of \(g\) at this point is also perpendicular to the path. Hence, the two gradients are pointing in the same direction. Figure 2 shows a depiction of this idea in 2D, where blue is our hill, red is our path and the arrows represent the gradient.
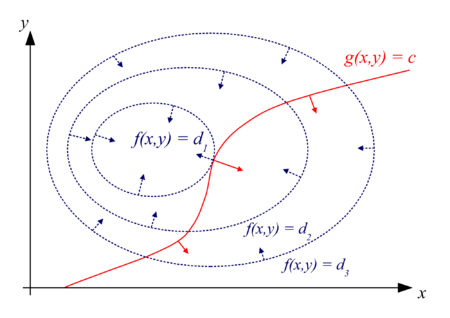
Figure 2: A 2D depiction of \(f(x,y)\) and \(g(x,y)=0\). The points on each ellipses define a constant height. The arrows define the direction of the gradient. (source: Wikipedia)
We can see that at our level point along the path, our red line is tangent to the contour line of the hill, thus the gradients point in the same direction (up to a constant multiplier). This makes sense because our path and the contour line follow the same direction (at least at that point), which means the gradients (which are perpendicular to the path) must be equal. Now there's no guarantee that the magnitudes are the same, so we'll introduce a constant multiplier called a Lagrange Multiplier to balance them. Translating that into some equations, we have:
Equation 1 is what we just described, and Equation 2 is our original condition on \(g(x,y)\). That's it! Lagrange multipliers are nothing more than these equations. You have three equations (gradient in two dimensions has two components) and three unknowns (\(x, y, \lambda\)), so you can solve for the values of \(x,y,\lambda\) and find the point(s) that maximizes \(f\). Note that this is a necessary, not sufficient condition. Generally the solutions will be critical points of \(f\), so you probably will want to find all possible solutions and then pick the max/min among those ones (or use another method to guarantee the global optima).
The Lagrangian
It turns out solving the solutions for Equation 1 and 2 are equivalent to solving the maxima of another function called the Lagrangian \(\mathcal{L}\):
If Equation 3 looks similar to the ones above, it should. Using the usual method of finding optima by taking the derivative and setting it to zero, we get:
As we can see, with a bit of manipulation these equations are equivalent to Equations 1 and 2. You'll probably see both ways of doing it depending on which source you're using.
Multiple Variables and Constraints
Now the other non-trivial result is that Lagrange multipliers can extend to any number of dimensions (\({\bf x} = (x_1, x_2, \ldots, x_n)\)) and any number of constraints (\(g_1({\bf x})=0, g_2({\bf x})=0, \ldots, g_m({\bf x}=0)\)). The setup for the Lagrangian is essentially the same thing with one Lagrange multiplier for each constraint:
This works out to solving \(n + M\) equations with \(n + M\) unknowns.
Examples
Now let's take a look at solving the examples from above to get a feel for how Lagrange multipliers work.
Example 1: Minimizing surface area of a can given a constraint.
Problem: Find the minimal surface area of a can with the constraint that its volume needs to be at least \(250 cm^3\).
Recall the surface area of a cylinder is:
This forms our "f" function. Our constraint is pretty simple, the volume needs to be at least \(K=250 cm^3\), using the formula for the volume of a cylinder:
Now using the method of Lagrange multipliers by taking the appropriate derivative, we get the following equations:
Solving 8, 9 and 10, we get:
Plugging in K=250, we get (rounded) \(r=3.414, h=6.823\), giving a volume of \(250 cm^3\), and a surface area of \(219.7 cm^2\).
Example 2: Milkmaid Problem.
Since we don't have a concrete definition of \(g(x,y)\), we'll just set this problem up. The most important part is defining our function to minimize. Given our starting point \(P\), our point we hit along the river \((x,y)\), and our cow \(C\), and also assuming a Euclidean distance, we can come up with the total distance the milkmaid needs to walk:
From here, you can use the same method as above to solve for \(x\) and \(y\) with the constraint for the river as \(g(x,y)=0\).
Example 3: Maximum likelihood estimate (MLE) for a multinomial distribution.
Problem: Suppose we have observed \(n\) rolls of a six-sided die. What is the MLE estimate for the probability of each side of the die (\(p_1, \ldots, p_6\))?
Recall the log-likelihood of a multinomial distribution with \(n\) trials and observations \(x_1, \ldots, x_6\):
This defines our \(f\) function to maximize with six variables \(p_1, \ldots, p_6\). Our constraint is that the probabilities must sum to 1:
Computing the partial derivatives:
Equations 13, 14, 15 gives us the following system of equations:
Solving the system of equations in 16 gives us:
Which is exactly what you would expect from the MLE estimate: the probability of a side coming up is proportional to the relative number of times you have seen it come up.
Conclusion
Lagrange multipliers are one of those fundamental tools in calculus that some of us never got around to learning. This was really frustrating for me when I was trying to work through some of the math that comes up in probability texts such the problem above. Like most things, it is much more mysterious when you just have a passing reference to it in a textbook versus actually taking the time to understand the intuition behind it. I hope this tutorial has helped some of you along with your understanding.
Further Reading
Wikipedia: Lagrange multiplier, Gradient
An Introduction to Lagrange Multipliers, Steuard Jensen
Lagrange Multipliers, Kahn Academy
- 1
-
This post draws heavily on a great tutorial by Steuard Jensen: An Introduction to Lagrange Multipliers. I highly encourage you to check it out.