Label Refinery: A Softer Approach
This post is going to be about a really simple idea that is surprisingly effective from a paper by Bagherinezhad et al. called Label Refinery: Improving ImageNet Classification through Label Progression. The title pretty much says it all but I'll also discuss some intuition and show some experiments on the CIFAR10 and SVHN datasets. The idea is both simple and surprising, my favourite kind of idea! Let's take a look.
Digression: This motivation in [1] is really good. They have this great spiel about how there is so much focus on improving the actual model and relatively little work on the other parts, in particular, the labels! What brilliant a statement! For any ML practitioner, they know that the most important part is the data, the model is a distant second. So why all the focus on the models? Well it's easier to publish I suppose and as a result probably the most interesting academically. Although I would guess some of the most cited papers are probably benchmark papers, so that's something. The people who are probably putting together really good datasets are probably making money off of them and not publishing. Go figure.
Label Refinery
Main Idea
Let's start off with the main idea because it's so simple. All we're going to do is train an image classification model, use its predicted outputs \(y'\) to train a fresh classification models using \(y'\) in place of the ground truth labels. That's right: we're using the predicted labels in place of ground truth labels! The claim is that this "refinement" step will improve your test accuracy. Figure 1 from the paper shows this visually.
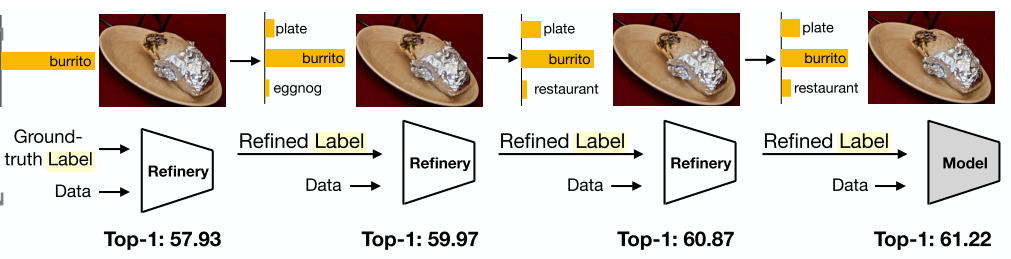
Figure 1: The basic idea behind Label Refinery (source: [1])
You can see at each iteration we're using the predicted labels ("Refined Label") to feed into the next model as the training labels. At some point, the last model in the chain becomes your classifier. Along the way, inexplicably, the accuracy improves.
In more detail, for a given image classification problem:
Set \(y = y_{\text{truth}}\) (ground truth labels).
Train a classifier \(R_1\) with images \(X\) and labels \(y\) from scratch.
Use \(R_1\) to predict on \(X\) to generate new "refined" labels, call it \(y_{R_1}\); set \(y=y_{R_1}\).
Repeat steps 1-2 several times to iteratively generate new models \(R_i\) and "refined" labels \(y_{R_i}\).
At some point, use \(R_i\) as your trained model.
Huh? Why should this even work? How can using a less accurate label (predicted output) to train result in better accuracy? It's actually quite simple.
Intuition
The big idea is that images can have multiple labels! Well... duh! However, this is a big problem for datasets like ImageNet where each image has exactly one label (i.e. a hard label). Take Figure 2 for example.

Figure 2: Illustration of multiple label problem (source: [1])
Figure 2 shows a picture of a "Persian cat" from ImageNet's training set. This label is not bad but you could also conceivably label this image as a "ball" too. This problem is magnified though when training a network using standard image augmentation techniques such as cropping. We can see the cropped image should clearly be labelled as a "ball" and not "Persian cat". However, if we add this augmented cropped image to our dataset, it will just add noise making it harder for the classifier to learn "Persian cat". On the other hand, if we use the label refinery technique above, we can have a soft labelling of the image. So it could be "80% persian cat" and "20% ball". This help reduce overfitting to the training images. The next figure shows another example of this.
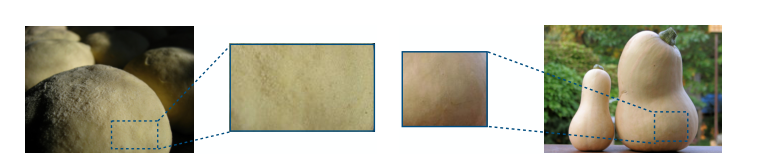
Figure 3: Examples of similar image patches. (source: [1])
Figure 3 shows examples of random crops of "dough" and "butternut squash". You can see that they are visually very similar. Similarly, if we use hard labels for the crops, we'll most likely have a very hard time learning the two because for two similar images we have completely different labels. Contrast that with having a soft label of "dough", "butternut squash", "burrito", "french loaf" etc. for the various patches.
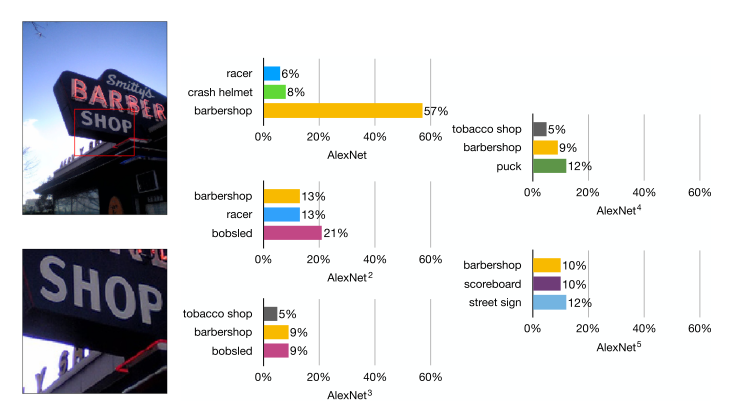
Figure 4: Examples of iterative refinement. (source: [1])
Figure 4 shows another example with the top three predictions at each iteration of label refinery trained on AlexNet. You can see that the first iteration overfits to "barbershop" especially when considering the cropped "shop" image. Using label refinery on the fifth iteration, we have a more reasonable soft labelling of "barbershop", "scoreboard", and "street sign" on the cropped image. (Hopefully "barbershop" still is ranked high for the original image!)
Experiments on CIFAR10 and SVHN
The experiments in [1] were all about improving ImageNet classification across its 1000 categories where the images were all relatively large in size (usually pre-processed to 256x256). I wondered how this idea would translate to other datasets that could run on my meager GTX 1070. To this end, I tried the label refinery method on two much easier datasets: CIFAR10 [2] and SVHN [3]. The former is a natural image dataset containing pictures of cars, animals, etc., while the latter is a bunch of images of street view house numbers.
Testing our hypothesis that label refinery works well because of our soft labels, we would expect that it might perform better on SVHN compared to CIFAR10 because SVHN will actually have multiple labels in the same picture (multiple numbers in the same image but only one hard label). Figure 5 and 6 show samples from the training data.

Figure 5: CIFAR10 Sample Images

Figure 6: SVHN Sample Images
Experimental Setup
I used the ResNet50 model from Keras as my base classifier replacing the last layer with a 10-way softmax dense layer (both datasets have 10 distinct labels). I also augmented the dataset with two times more images with random 10 degree rotations, 10% zoom and 10% shifts in X or Y directions with an additional random horizontal flip for CIFAR 10. I used the ImageDataGenerator class from Keras to make the augmented images. Usually for ImageNet you actually do a crop but since the images are so small it doesn't quite make sense to do that.
Some other details from the implementation:
The standard test set was used from both datasets
15% validation set from the training set
Categorical cross-entropy loss
Used Adam optimizer with reduced learning rate on loss plateau and early stopping based on the validation set accuracy
Each combination below was run 5 times and the mean test accuracy and standard deviation are reported
All the code can be found here on Github.
Experimental Results
Finally, let's take a look at the experiments! Table 1 shows the results on both datasets.
Table 1: Label Refinery Experiments with CIFAR10 and SVHN datasets with and without image augmentation.
CIFAR10 |
SVHN |
|||
Label Refinery Iteration |
Augment=0 |
Augment=1 |
Augment=0 |
Augment=1 |
\(R_1\) |
62.9 ± 6.7 |
68.7 ± 4.5 |
88.1 ± 2.7 |
91.0 ± 2.1 |
\(R_2\) |
44.2 ± 20 |
64.2 ± 11 |
73.1 ± 30 |
91.5 ± 1.3 |
\(R_3\) |
32.3 ± 22 |
59.0 ± 12 |
73.9 ± 31 |
91.5 ± 1.2 |
From Table 1, the first column shows the label refinery iteration. \(R_1\) means the first classifier in the refinery chain (using the ground truth labels), \(R_2\) means we took the output of \(R_1\) and used it as labels for training \(R_2\) etc. I also show results with and without the described image augmentation.
The first thing to notice is that image augmentation works pretty well! The test set accuracy on the base classifiers go from 62.9% to 68.7% and 88.1 to 91.0% on CIFAR10 and SVHN respectively. That's pretty good for just doing some simple transformations on images. It makes sense since the content of images are, for the most part, invariant to small perturbations. This basically just adds more varied training data, which of course will make the classifier stronger.
The second thing to notice is that the label refinery technique performs poorly on the CIFAR10 dataset. I suspect that the main reason is the hypothesis we stated above: the soft labels don't really help because there is no overlap in labels in the pictures. We can see that the performance varies so widely in latter iterations.
Taking a look at SVHN, we see that without augmentation label refinery shows similarly poor results. However with augmentation, we do see some marginal, relatively stable improvement from 91.0% to 91.5% mean test set accuracy. Although I should note that it only actually improved results on the second iteration in 3 out of the 5 runs. In the other two runs, it went from 92.5% to 91.5% to 91.9%, and 92.6% to 92.5% to 92.9%. So still pretty good, with only one run showing somewhat of a decrease.
Relating this back to the hypothesis above, here are some thoughts:
We actually have a use for the soft labels because some images indeed do have multiple labels (more than one number in the image).
The augmentation might be needed with label refinery because the number of images with multiple numbers is not very large, thus it is not able to make use of multiple labels efficiently otherwise (the training algorithm might just treat them as noise).
Along these lines, the classifier is able to learn more generalized digits with the augmented images and soft labels. For example, an image might be labelled "3" but have numbers "123". If we shift and zoom in on it, it might only show "12". The soft labels of course will help in this case, but it also gives the classifier a chance to see additional examples of "1" and "2", increasing its generalizing capability.
The effect on SVHN is still relatively small though, most likely because the label overlap problem is not as severe as ImageNet where they do actual cropping.
Conclusion
Sometimes we focus too much on the super sexy models that do funky things like GANs or Deep RL (or variational autoencoders!) and often don't pay much attention to some of the simpler ideas. I really like simple yet robust ideas like this label refinery because they usually end up being more useful as well as more insightful. It would be cool if label refinery could be applied to other types of domains like numeric predictions but I don't think the effect would translate to non-images. I'm working on another post but it might take a while to get out because I'll be taking some vacation and will be super busy in the fall. Hopefully, I'll find some time in between to push it out before the end of the year. Thanks for reading!
Further Reading
Previous posts: Residual Networks
My label refinery code: Github
[1] Label Refinery: Improving ImageNet Classification through Label Progression, Hessam Bagherinezhad, Maxwell Horton, Mohammad Rastegari, Ali Farhadi
[2] CIFAR-10 Dataset
[3] SVHN Dataset